OpSec for Celebrities
In the wake of, again, leaked nude pictures of celebrities, a little crash course can be useful. It doesn't matter it's wrong to force access to private data and it doesn't matter the perpetrators will eventually be caught and punished. Someone else will do it again. They always do. Below you'll find some tips you may want to follow, even if you are not a celebrity.
Programming iOS 5, 2nd Edition, by Matt Neuburg
I'll start by saying this book is not for beginners. If you never wrote a program before, this book is not for you.
Programming iOS 5 (and its later edition) may very well be the book you need to read in order to develop for iOS devices. It serves as an introduction to Objective-C (which some people regard as what C++ should have been from the start), a thorough guide to the XCode IDE you'll use to develop your apps, to the Cocoa collection of frameworks and their user interface concepts. If you already program, the introduction to Objective-C, along with the recommended K&R re-reading, should make you comfortable with the language. The XCode IDE may take a little more time to get used to if you are too accustomed to other IDEs (or even a command-line plus plain editor mindset), but the book does a nice job explaining it. The same is true for the large set of Cocoa frameworks required to effectively build iOS applications (with a nice side effect of giving you some head start with MacOS development) the book covers.
Dated look
I know. This site still runs on Plone 2 with the help and immense competence of my friends at Simples Consultoria and looks obviously dated. With any luck, my work on transmogrifier tools will allow it to smoothly migrate to a new Plone 4 instance in the near future. Stay tuned.
Reverse scrolling on Linux, but only when it makes sense
It's hard not to think that the idea of dragging the document instead of the viewport makes sense, in special if your trackpad supports two-finger dragging. It also feels very natural to have things like inertia (when the document continues to scroll when you release the pad with your fingers moving and gradually slows down - or halts when you stop it with your finger) in this mode.
Unfortunately, the only way to enable reverse scrolling (and we are not even considering inertia) on Linux is through an xmodmap hack that affects every pointing device. Even more unfortunate, this mode makes absolutely no sense when you are using a clickwheel (such as the one on your mouse) to scroll.
To that end, I published a post on Ubuntu Brainstorm. If you like the idea, please, express your support.

Benedetti and Cranley's Head First jQuery
A very helpful book for those who want to get familiar with jQuery. The examples cover a great deal of common-use functionality and offer some guidance on better practices and style for those who are unfamiliar to modern JavaScript programming.
SOPA, PIPA and our lost innocence
Today many websites are engaged in protests. They protest against abusive and oppressive laws proposed by corporations who are unwilling to adapt to the new reality they found themselves in. Corporations who have corrupted representatives in many countries (albeit the protest is against two laws being considered in the United States, similar laws exist and are being considered all over the world) threaten to enable corrupt governments to quickly and swiftly silence any opposition. For these dinosaurs to survive, our new world of free exchange of ideas must die. We must not allow that to happen.
Update on the SOPA supporter list
Since originally posted, the SOPA supporter list has moved and changed. Some interesting additions, some interesting removals.
Companies that support SOPA
Here is a handy list, copied on 2011-12-22, 21:30 UTC from http://judiciary.house.gov/issues/Rouge%20Websites/SOPA%20Supporters.pdf, of the companies that openly support SOPA. It's handy in case some lobbyist persuades the US House of Representatives to remove the original file
Supercharged JavaScript Graphics, by Raffaele Cecco (O'Reilly, 2011)

I loved reviewing this book. Not only I learned a lot of new, cool tricks, the methods, tools and techniques I learned, from JavaScript code optimization to proper usage of jQuery Mobile and PhoneGap, were well worth the time invested in reading the book. The text flows well and the examples are easy to follow, understand and apply to your projects. When there is more ground to be covered, the book will point you in the right direction to continue playing with the technologies introduced.
Fair warning: JavaScript can be very alien to people who come from other languages and you have to be reasonably proficient with JavaScript to make full use of this book.
You can find this book at the O'Reilly website or on Amazon.
Disclosure: This book was provided by O'Reilly Media as part of their blogger review program. The version reviewed was the ePub version on a 1st-gen B&N Nook. All formats are DRM-free.
More Emacs - a better eshell
Some Emacs users live their entire lives without ever meeting eshell. Eshell is a command-line shell where you can run programs, list directories, copy files and do all kinds of things you would normally need a terminal window for. Eshell even made a cameo appearance in Tron Legacy, as the command-line interface to Encom's computers. Unfortunately, there is something it won't do: it's not easy to start more than one eshell session - when you invoke eshell for the second time, it goes back to the buffer the first eshell opened, normally called "*eshell*". I could invoke the "rename-uniquely" command manually after opening each eshell window (or before attempting to open a new one), but that's annoying (and I ofen forget it).
I keep eshell bound to C-$ (control-$ for the emacs-illiterate ou ^$ for really old-school folks - not that any keyboard I know of emits valid ASCII when someone presses Control-$). I often need more than one shell. "ansi-term" will do the buffer-renaming magic and I can start a number of those, but that's not really what I want - ansi-term runs the shell as a separate process. I use it when I need things I'd need another terminal for, like input and output redirection, but I'd prefer to use eshell when all I need is another shell.
Unfortunate people who don't use Emacs will think I would need to dig up the sources of eshell to add the rename-uniquely invocation and change them. I'll remind those poor folks than your init.el file is, in fact, executed when Emacs starts and, therefore, all I need to do is to change my binding from
(global-set-key (kbd "C-$") 'eshell)
to
(global-set-key (kbd "C-$") '(lambda () (interactive) (eshell) (rename-uniquely) ))
In case you are wondering, the "interactive" function is invoked to mark this function as a command. If I didn't do it (as I foolishly did earlier this morning, before reading this) I'd be greeted with
Wrong type argument: commandp, (lambda nil (eshell) (rename-uniquely))
That's nice, but not perfect. If you invoke it, you will notice your first eshell buffer is named "*eshell*<2>". That's bad.
It happens because the buffer is uniquely renamed every time it's created, not only when there already is a buffer named "*eshell*". For that, we need a little more code:
(global-set-key (kbd "C-$") '(lambda () (interactive) (if (member "*eshell*" (mapcar* 'buffer-name (buffer-list))) (progn (eshell) (rename-uniquely)) (eshell))))
OK. That was stupid. We test whether there is already a buffer named "*eshell*" and then we try to invoke eshell to create a new one, forgetting that eshell will also find the buffer called "*eshell*" and switch to it rather than creating a new one. We then, dumbly, rename our only eshell buffer.
This thing needs more brains.
Since I don't expect to have more than a handful eshells running (you really shouldn't try to), progressing through numbered buffer names until we find a free one should be a fine approach:
(global-set-key (kbd "C-$") '(lambda ()
(interactive)
(let ((i 1)
(found-a-name nil))
(while (not found-a-name)
(setq buffname
(concat "*eshell*<" (int-to-string i) ">"))
(setq found-a-name (not (member buffname
(mapcar* 'buffer-name
(buffer-list)))))
(if found-a-name
(eshell i)
(setq i (+ i 1))
)))))
Now we start from i = 1 and check if there is already a buffer named "*eshell*<i>". If there is not, create one with that name (passing the number to eshell) and end our search. This is doubly pretty, because the first solution would rename our first eshell as "*eshell*<2>". With this one, the first eshell is "*eshell*<1>", which is elegant. If you manually open an eshell, it'll be called "*eshell*", distinguishing it from our automatically named shells.
Still, as a friend of mine well pointed out, the code is really ugly. It'll also fail if the default name for eshell buffers is changed. In short, it's a mess. I felt compelled to do better:
(global-set-key (kbd "C-$") '(lambda () (interactive) (let ((i 1)) (while (member (concat eshell-buffer-name "<" (int-to-string i) ">") (mapcar* 'buffer-name (buffer-list))) (setq i (+ 1 i))) (eshell i))))
Much more concise and to-the-point. I like it.
Can you customize Eclipse like that?
A bug. Yes, they hit me too
After publishing this, I noticed the variable eshell-buffer-name is not defined until after you invoke eshell for the first time. If you try to C-$ on a freshly started Emacs session, you'll get a
Symbol's value as variable is void: eshell-buffer-name
message. In order to fix this, the code must check whether eshell-buffer-name is bound and, if it's not, we start the buffer giving it a 1.
(global-set-key (kbd "C-$") '(lambda () (interactive) (let ((i 1)) (if (boundp 'eshell-buffer-name) (progn (while (member (concat eshell-buffer-name "<" (int-to-string i) ">") (mapcar* 'buffer-name (buffer-list))) (setq i (+ 1 i))) (eshell i)) (eshell 1)))) )
OK. Now I am satisfied.
Edit: And now, I feel stupid
A friend of mine, very politely, possibly to avoid embarrassing me in public, sent me an e-mail pointing out he didn't quite understood what I was trying to accomplish here. In his message, he pointed out I could just invoke (eshell t). When passed "t" (boolean true in Lisp) as a parameter, eshell does precisely what I wanted it to do. So, the new version in my init.el is even shorter:
(global-set-key (kbd "C-$") '(lambda () (interactive) (eshell t)))
Well... At least I learned something.
Emacs perfection - selecting fonts according to screen size
Most of the time, I work at my desk, where my netbook is hooked up to a reasonably sized monitor (the largest its feeble GPU can handle with acceleration). Since screen real-estate in that situation is abundant, I opted to use a larger font (one I made from the x3270 bitmap font, but that's another, much longer story). Unfortunately, when I am not at my desk, the 1024x600 LCD is quite limiting and the default options don't work for me. When I am away from the big screen monitor, screen real-estate is limited and a small font should be selected by default.
I started from the options the Custom menu gave me. Removing comments, it's a very simple snippet:
(custom-set-faces
'(default ((t (:inherit nil :stipple nil :inverse-video nil :box nil :strike-through nil :overline nil
:underline nil :slant normal :weight normal :height 140 :width normal :family "IBM 3270"))))
'(linum ((t (:inherit default :foreground "#777" :height 110)))))
Translating that to English, I have a font called "IBM 3270" at a 14-point height, with line numbers with 11 points. Very readable.
But that doesn't solve the problem when I am on the road.
The friendly guys at Stack Overflow pointed out one way to do it: x-display-pixel-width and x-display-pixel-height.
With that in hand, I can do:
(if (> (x-display-pixel-width) 1280)
; screen is big
(custom-set-faces
'(default ((t (:inherit nil :stipple nil :inverse-video nil :box nil :strike-through nil :overline nil
:underline nil :slant normal :weight normal :height 140 :width normal :family "IBM 3270"))))
'(linum ((t (:inherit default :foreground "#777" :height 110)))))
; screen is small
(custom-set-faces
'(default ((t (:inherit nil :stipple nil :inverse-video nil :box nil :strike-through nil :overline nil
:underline nil :slant normal :weight normal :height 110 :width normal :family "IBM 3270"))))
'(linum ((t (:inherit default :foreground "#777" :height 80)))))
)
and I can be happy.
But can I?
When I start Emacs without X (as in from a remote terminal), these functions issue an ugly warning telling me that X is not available and that I should --debug-init and fix the problem. That's safely ignorable (as these adjustments are being done when everything non-cosmetic is already in place, at least in my init.el), but, still, annoying.
There is a variable, window-system, that can help - it holds "x" if we are under the X windowing system and nil if we are using a character terminal. With it, I can do:
(if (and (eq 'x window-system) (> (x-display-pixel-width) 1280))
; screen is big
(custom-set-faces
'(default ((t (:inherit nil :stipple nil :inverse-video nil :box nil :strike-through nil :overline nil
:underline nil :slant normal :weight normal :height 140 :width normal :family "IBM 3270"))))
'(linum ((t (:inherit default :foreground "#777" :height 110)))))
; screen is small
(custom-set-faces
'(default ((t (:inherit nil :stipple nil :inverse-video nil :box nil :strike-through nil :overline nil
:underline nil :slant normal :weight normal :height 110 :width normal :family "IBM 3270"))))
'(linum ((t (:inherit default :foreground "#777" :height 80)))))
)
short-circuiting the x-display-pixel-width and allowing Emacs starts cleanly from a remote terminal session. Since window-system also can tell you if you are on a Mac (or NeXT, if you are into retrocomputing) or under Windows (you can't argue taste), you can take appropriate actions according to your environment.
I am happy for today.
The Manga Guide to Relativity
Physics is an intimidating subject this (comic-)book manages to tackle in a way most teenagers will find easy to understand. More to the point, they will, hopefully, find it fun and compelling too. Its structure is a good fit for high-school teenagers (don't traumatize your 10-year-old kid with it) with an interest for science and/or Japanese comic-books.
Dorneles Treméa's day
Yesterday, in my e-mail, I had this message:

Today would be the birthday of a good man. Smart, fun, generous, unbeatable Wii Tennis player, father of a family I only met in pictures and a friend I should have met more often. There is no pythonista or plonista in Brazil that doesn't have a debt of gratitude towards him. His dedication and generosity were a fundamental part of our history, made our lives better and serve as an inspiration for our future deeds.
Today this blog joins many others. Today is #dornelesday.
It's a day to remember him.
Every day is a day to follow his example.
Learning Android, by Marko Gargenta
This is a fairly good book that will take you through your first steps on Android application development. It goes over key concepts like activities, services, intents and asynchronous tasks, explores the helpers and builders in Eclipse (but does not refrain itself from going into the XML when needed) and does so by going through the development of a simple application. I think the best way to go through this book is to follow along and build your own. If the book has any weak spot, it's the sample application. For a book like this, I would not use a Twitter client - the Twitter API introduces some needless complexities into what should be a trivial example (and I, most certainly, don't want to develop yet another Twitter client). By going with a Twitter client, the book also somewhat limits itself to a certain narrow usage example and that affects what the book covers in terms of UI and tooling.
It took me a while to get through it because I opted to write an application different from the Yamba example (for the reasons I stated above). If you decide to go closely with the book example, you should do it in about a week. It also didn't help me the fact I could not dedicate more than a couple hours per week to the project.
A final piece of advice: I reviewed the ePub version on a Nook. The screen images were somewhat hard to read and I had to use the PDF version to see some of the finer detail. I am not sure whether this is a problem with the ePub version or with my specific e-reader (it has some issues). Your mileage may vary.
Pros: Short, easy to understand, well written
Cons: The example app is not perfect for the task
Best uses: Those new to Android
Matthew Russell's 21 Recipes for Mining Twitter
This is a very short, very practical way to get you started exploring the Twitter APIs on your own. It offers a decent amount of code no experienced developer should have much trouble understanding and applying to his or her own needs. The cost per page is not exactly attractive and some readers may want a more in-depth less cookbook-like experience. If you are in a hurry to extract data from Twitter, this book may be for you - for less than $20 for the electronic edition, it will spare you more than that in time spent figuring out libraries and APIs. Plus, it offers some intro on many other interesting libraries that can be applied to a lot of problems besides Twitter mining.
You can buy the book from Amazon or directly from O'Reilly.
The fainting surgeon
This morning I came across a funny comment.
On a post that highlights a subtle implication of the use of Java and as a teaching tool (picked up on another article, this one about Scheme), a guy named Stephen Fraser dropped this: "As I see it, a software engineer who hasn’t worked through SICP with Scheme, a basic editor and command line, is like a surgeon who has never dissected a frog and faints at the sight of blood."
I happen to agree with that. It's not as much a virtue of Scheme and SICP (both outstanding teaching tools), but a major conceptual failure of IDEs. By shielding the programmer from the complexities (and we can endlessly argue whether those are needed or not) of the typical Java framework or build tool, they make that complexity tolerable and thus create fertile ground for adding new complexities on top of it the already high pile of complexity, a layer that will, eventually, be mitigated by the next iteration of the IDE (or, if this specific layer of complexity fails to get much traction, by an IDE plugin).
And so, as we add layer upon layer of complexity, many of today's software engineers grow accustomed to be so removed from whatever they are actually doing (or, more precisely, what their IDEs are doing for them) that they risk being unable not only to see, but to accurately grasp the full depth of the stack they are standing upon. They become surgeons who can't say where the patient's lungs are located or what they do.
Mining the Social Web, by Matthew A. Russell
 This book covers a lot of ground. It's, at times, a bit vertiginous in the amount of subjects and technologies it touches per chapter, and is not always easy to follow. It can also introduce so many interesting things that, by the time you finished becoming familiar with all of them, after wandering for hours on the web, jumping from interesting technology to interesting technology, you may have forgotten what took you to these places and wonder where you were in the book. Time spent reading it is, however, time very well spent. When you finish it, you will have at least a cursory familiarity with tools like OAuth, CouchDB, Redis, MapReduce, NumPy (and the Python programming language, albeit it will help you a lot if you know your way around Python before you start the book), Graphviz, SIMILE widgets, NLTK, various service APIs and data formats, and will be well equipped to explore those rich datasets on your own. The chapters are well compartmentalized and it's easy to pick chapters to read according to your needs. I know that, when I face the problems they tackle, I will do exactly that.
This book covers a lot of ground. It's, at times, a bit vertiginous in the amount of subjects and technologies it touches per chapter, and is not always easy to follow. It can also introduce so many interesting things that, by the time you finished becoming familiar with all of them, after wandering for hours on the web, jumping from interesting technology to interesting technology, you may have forgotten what took you to these places and wonder where you were in the book. Time spent reading it is, however, time very well spent. When you finish it, you will have at least a cursory familiarity with tools like OAuth, CouchDB, Redis, MapReduce, NumPy (and the Python programming language, albeit it will help you a lot if you know your way around Python before you start the book), Graphviz, SIMILE widgets, NLTK, various service APIs and data formats, and will be well equipped to explore those rich datasets on your own. The chapters are well compartmentalized and it's easy to pick chapters to read according to your needs. I know that, when I face the problems they tackle, I will do exactly that.
If you do any kind of analysis and visualization of social-generated data that's on the web, this book is a good pick. Even if your datasets are not from the web, you may find the parts on analysis and visualization very interesting.
You can find this book at the O'Reilly website or on Amazon.
Disclosure: I reviewed this book for the O'Reilly Blogger Review Program. If you have a blog and love to read, you should take a look into it. It's fun.
The Facebook Marketing Book, by Dan Zarrella

Facebook Marketing is not a book for programmers. For us, it's a very hard read and finishing it took some determination. Neither it is for startups that intend to be the next Zynga, as it offers little advice for those, specially with regard to monetization options. It contains, however, good advice for already established entities that want or need to use Facebook as a vehicle for engaging current and acquiring new clients that's specially valuable if you are new to the social networking environment. It also contains an overview on how to employ Facebook's functionalities as tools to promote your brand, for communicating and organizing social events and on what kinds of content you should generate to keep your Facebook assets alive. It offers some advice that's useful for hackers like me, on how to best model the social relations of a Facebook application to ensure it has chances of becoming viral.
You can find more about the book on O'Reilly's site and on its Amazon page.
HTML5: Up and Running - A fun-to-read intro to HTML5

This is a well written, fun to read book on what is new in HTML 5, why it's important and how it came into existence. It introduces new tags, reminded me of some old and forgotten and, in general, improved the quality of the HTML I write. It also presents Modernizr, a feature-detection framework (which is a much better idea than trying to parse the user-agent string). The book has an associated website where most of its text is available (albeit in a less couch-friendly format than the book/e-book and that does little to support the author) and both book and site have been important companions on my quest to relearn HTML and to get rid of any bad habits I may have developed in the past 15 years.
You can find the book at O'Reilly's site.
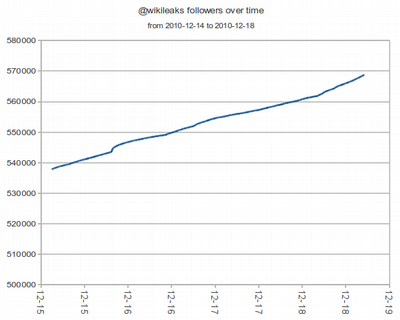
Wikileaks followers, a thousand data-points later
A couple days back, I measured how the Twitter @wikileaks account was gaining followers. I suspected my dataset was biased, since it was captured on a Saturday night (here, GMT-2) and that I would see different values according to time of day. I decided it was a nice idea to focus my analysis tool on the account and keep it capturing data for a longer time. To my surprise, it's still a more or less straight line. I still think they'll cross the million follower mark in early-to-mid February. This could indicate Wikileaks is gaining followers around the globe (or, at least, evenly distributed according to time-zone) or that the people who follow @wikileaks don't follow conventional sleep cycles.
 Previous:
Five reasons why this developer won't switch to Mac
Previous:
Five reasons why this developer won't switch to Mac